BridgeV2W bridges pretrained video generation models to embodied world models via embodiment masks that align actions with pixel spaces, while ensuring viewpoint robustness, embodiment-agnostic architectures, and effective reuse of pretrained visual and motion priors.
Embodied world models have emerged as a promising paradigm in robotics, most of which leverage large-scale Internet videos or pretrained video generation models to enrich visual and motion priors. However, they still face key challenges: a misalignment between coordinate-space actions and pixel-space videos, sensitivity to camera viewpoint, and non-unified architectures across embodiments. To this end, we present BridgeV2W, which converts coordinate-space actions into pixel-aligned embodiment masks rendered from the URDF and camera parameters. These masks are then injected into a pretrained video generation model via a ControlNet-style pathway, which aligns the action control signals with predicted videos, adds view-specific conditioning to accommodate camera viewpoints, and yields a unified world model architecture across embodiments. To mitigate overfitting to static backgrounds, BridgeV2W further introduces a flow-based motion loss that focuses on learning dynamic and task-relevant regions. Experiments on single-arm (DROID) and dual-arm (AgiBot-G1) datasets, covering diverse and challenging conditions with unseen viewpoints and scenes, show that BridgeV2W improves video generation quality compared to prior state-of-the-art methods. We further demonstrate the potential of BridgeV2W on downstream real-world tasks, including policy evaluation and goal-conditioned planning.
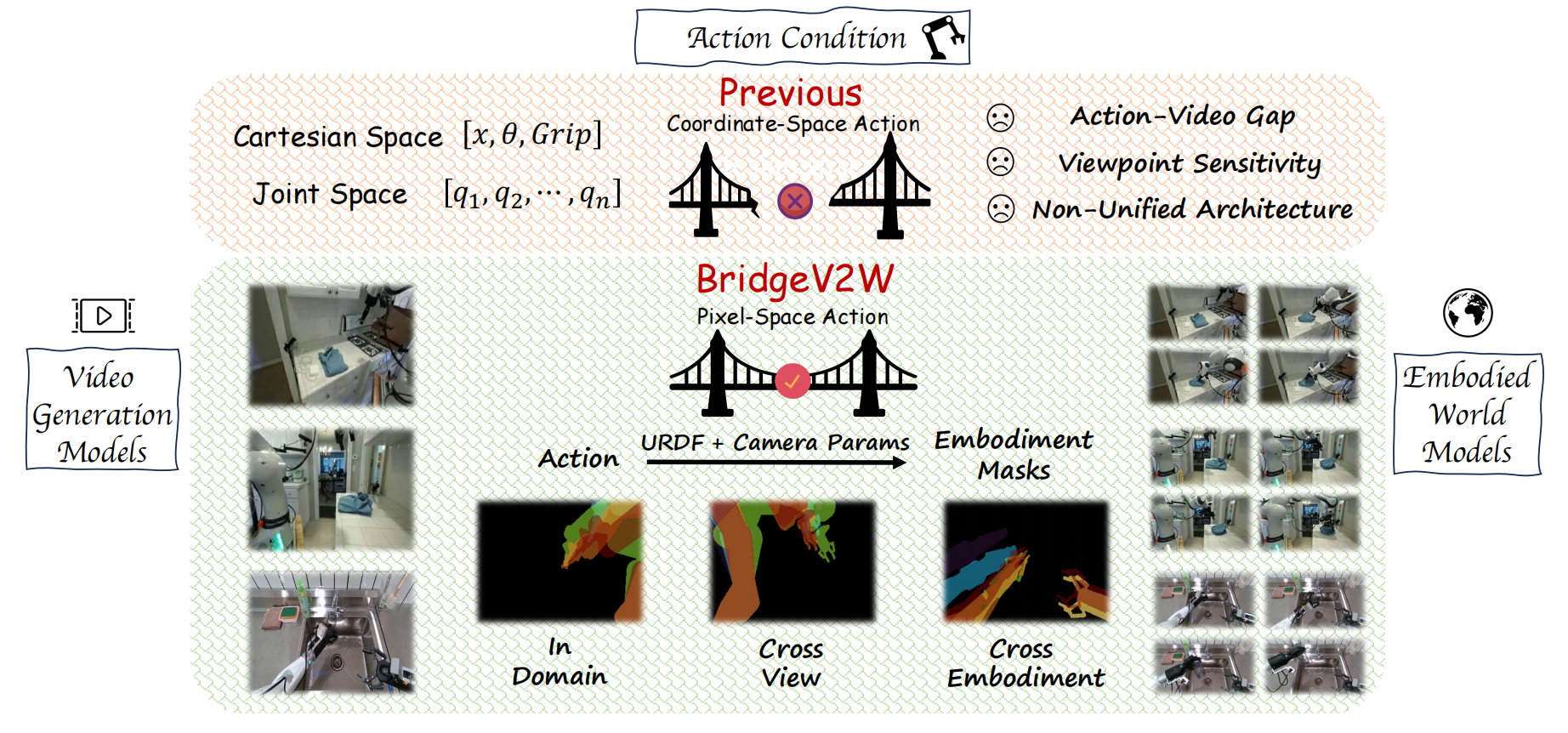
Figure 1: BridgeV2W vs. previous methods. Pixel-aligned embodiment masks bridge video generation models to embodied world models, addressing the action–video gap, improving viewpoint robustness, and yielding a unified architecture across embodiments.
BridgeV2W is an action-conditioned embodied world model that predicts future videos from an initial image and an action sequence. The core idea is to bridge actions into the visual domain by converting them into pixel-aligned embodiment masks and injecting them into a pretrained video diffusion model.
The action-to-mask conditioning module converts coordinate-space actions into pixel-aligned embodiment masks rendered from the URDF and camera parameters.
Standard diffusion losses supervise frames independently and may overlook temporal structure. To improve spatiotemporal consistency, BridgeV2W combines two motion-aware objectives:
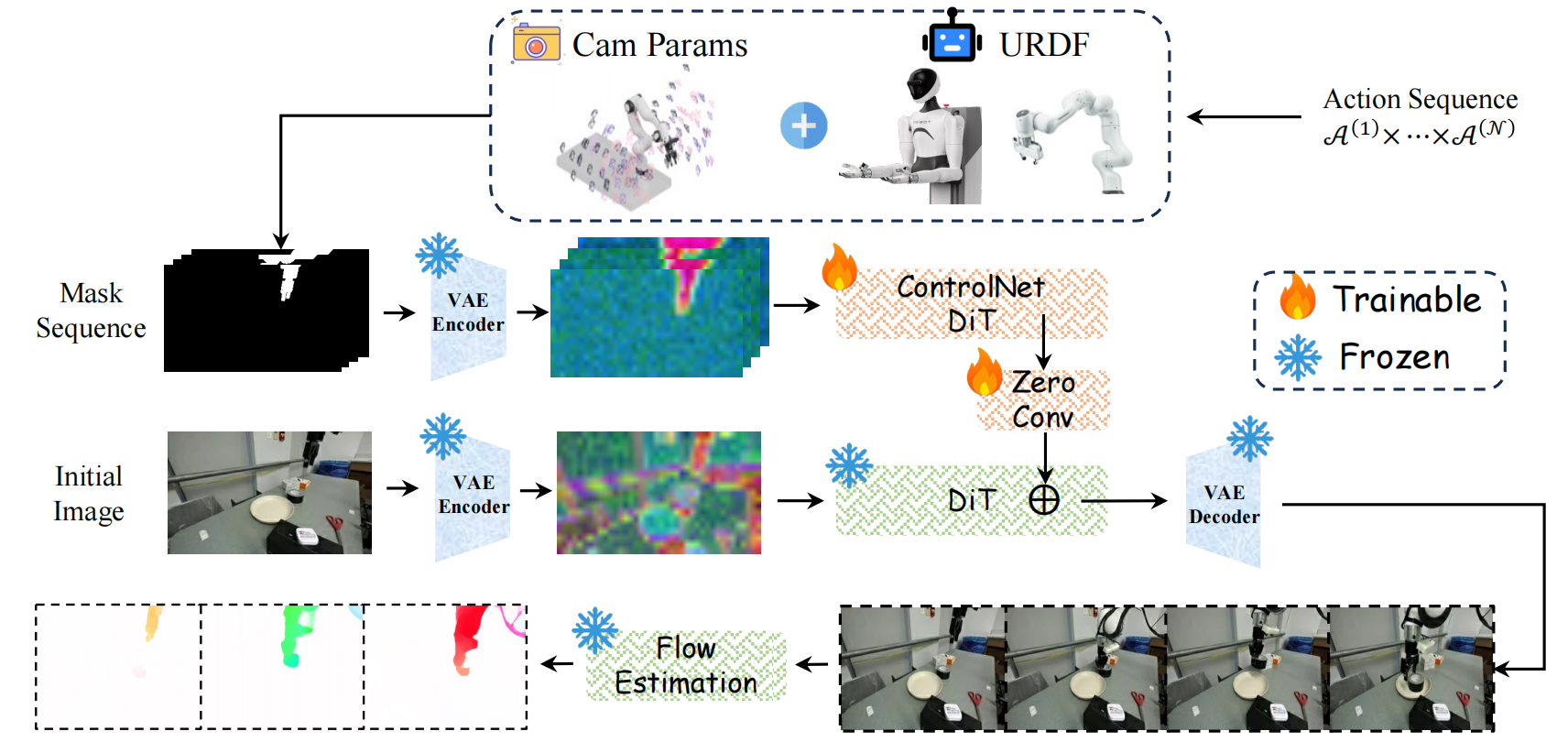
Figure 2: Overview of the BridgeV2W pipeline. Actions are projected into pixel-space masks using URDF and camera parameters. The initial image and mask sequence are encoded by VAE, with mask features injected via a ControlNet branch into the DiT backbone. The model generates action-consistent videos, trained with diffusion, dynamics-consistency, and flow-based objectives.
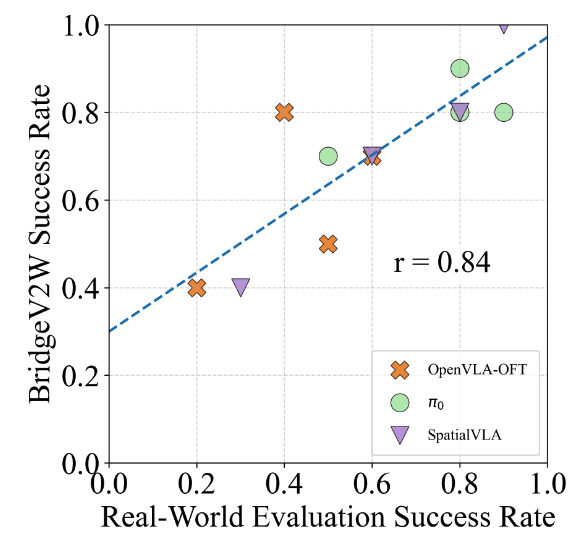
Figure 3: Correlation between BridgeV2W evaluation and real-world success.
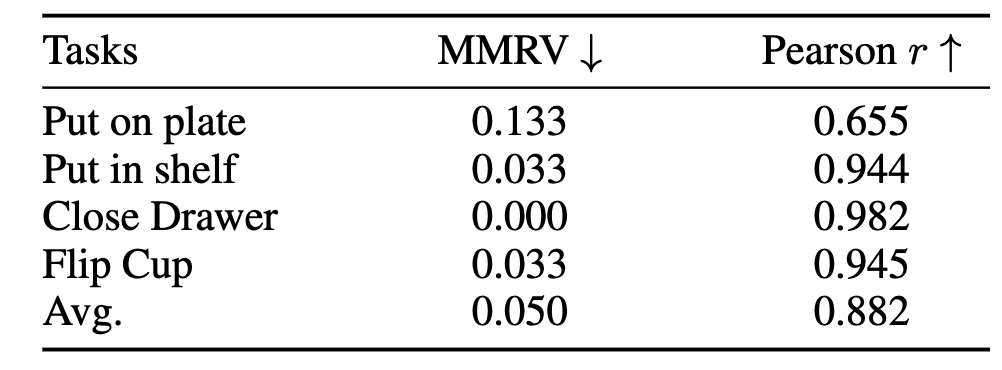
Table 1: Policy evaluation across tasks and baselines using BridgeV2W.
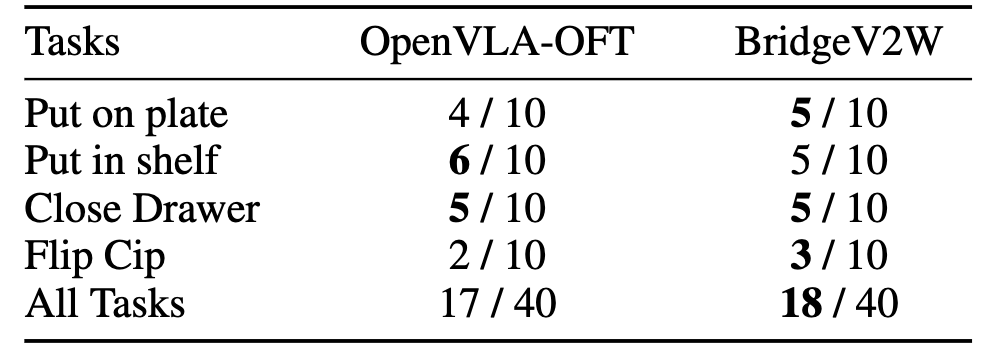
Table 2: Real-world planning performance with BridgeV2W.
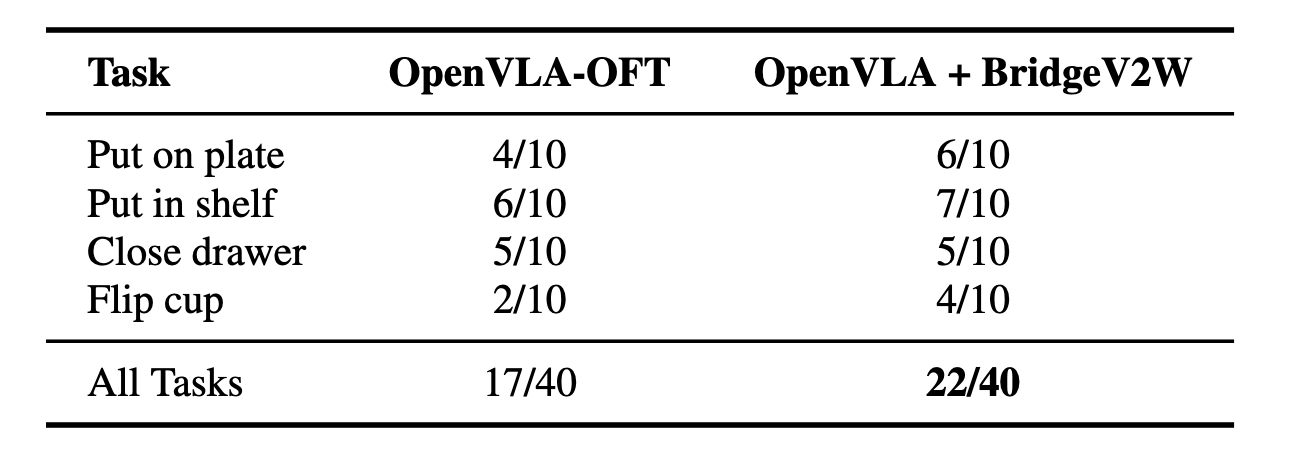
Table 3: Real-World success rates with BridgeV2W + OpenVLA-OFT.
@misc{chen2026bridgev2wbridgingvideogeneration,
title={BridgeV2W: Bridging Video Generation Models to Embodied World Models via Embodiment Masks},
author={Yixiang Chen and Peiyan Li and Jiabing Yang and Keji He and Xiangnan Wu and Yuan Xu and Kai Wang and Jing Liu and Nianfeng Liu and Yan Huang and Liang Wang},
year={2026},
eprint={2602.03793},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2602.03793},
}